オンデバイスAI文字起こし vs クラウド:プライバシー・速度・精度を比較
オンデバイス音声認識とクラウド文字起こしを徹底比較——プライバシー、レイテンシー、精度、コストの観点から分析します。
根本的な問い:音声データはどこへ行くのか?
文字起こしアプリで「録音」をタップするたびに、根本的な選択が行われています。音声はデバイスに留まるのか、それとも遠く離れたサーバーへ送信されるのか。この問いは音声認識技術における最大の分岐点となっています。
Apple がiOS 26でSpeechAnalyzerフレームワークを発表したことで、完全なオンデバイス文字起こしは妥協ではなく、クラウドサービスの本格的な代替手段となりました。
プライバシー:音声をローカルに保持する意味
オンデバイス文字起こしとは文字通り、音声がスマートフォンの外に出ないことを意味します。
- データ送信ゼロ — 音声パケットが外部サーバーに送られることはありません。傍受、漏洩、召喚令状の対象になるものがありません。
- サードパーティ処理なし — クラウドプロバイダーは共有インフラで音声を処理します。転送中の暗号化があっても、データは他者のハードウェア上に一時的に存在します。
- 規制遵守 — 医療(HIPAA)、法律(弁護士・依頼者間秘匿特権)、金融(SOX/GDPR)の専門家にとって、オンデバイス処理はコンプライアンスリスクのカテゴリー全体を排除します。
速度とレイテンシー:即時 vs ネットワーク依存
オンデバイス文字起こしは、話し始めた瞬間からテキストを生成します。リモートサーバーとのハンドシェイクも、音声チャンクのアップロード待ちも、往復遅延もありません。
クラウド文字起こしには固有のレイテンシーがあります:音声のキャプチャ、パケット化、サーバーへの送信(ネットワーク状態により50〜200ms)、処理、結果の返送。高速Wi-Fiでは気にならないかもしれませんが、混雑した携帯回線や電波の悪い会議室では遅延が顕著になります。
精度:各アプローチの得意分野
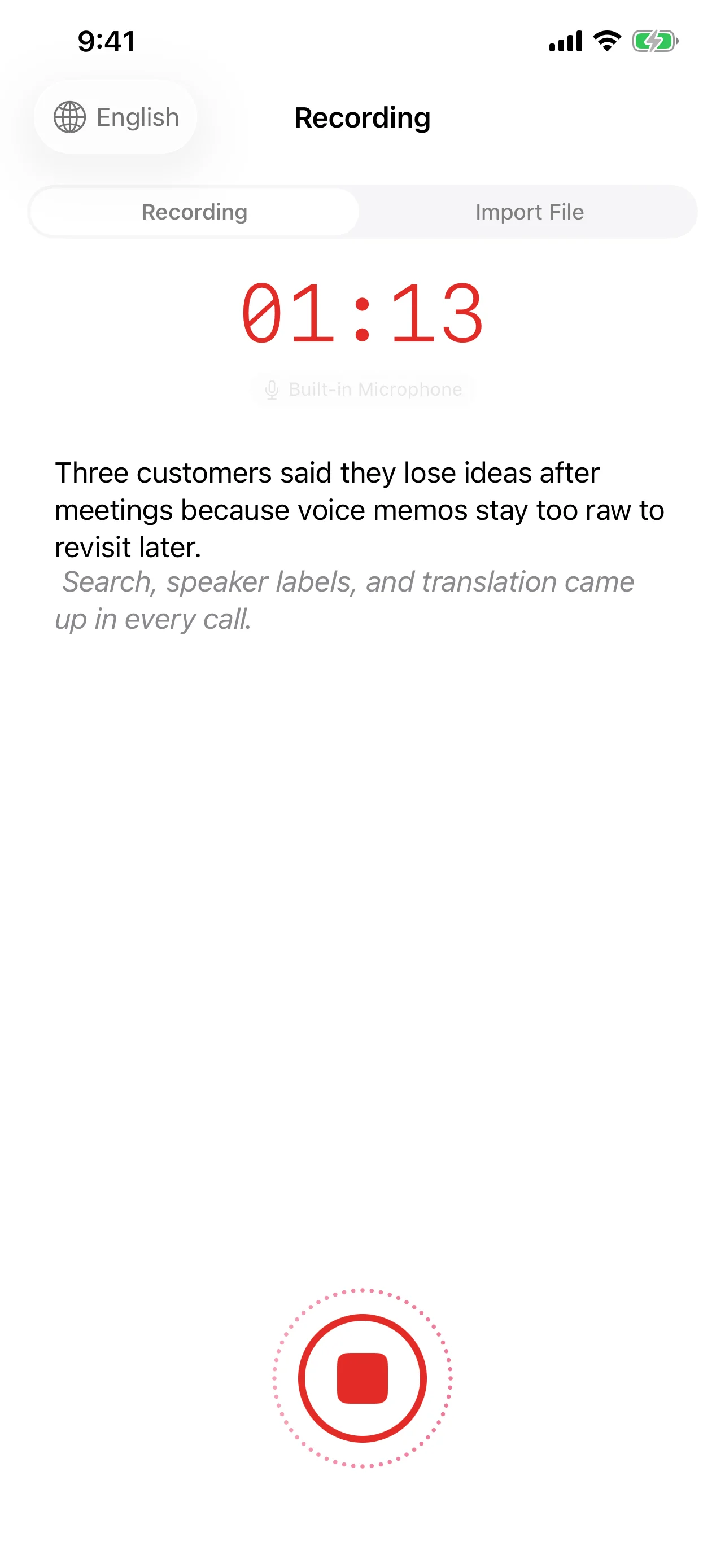
オンデバイスの強み:
- 一般的な言語と標準的な語彙に優れた性能
- ネットワーク状態に関係なく一貫したパフォーマンス
- SpeechAnalyzerのDictationTranscriberによる自動句読点で、出力がすぐに読みやすい
- 話者分離が完全にオフラインで動作
クラウドの強み:
- より大きなモデルが、珍しい言語、強いアクセント、専門用語をより確実に処理
- 継続的なトレーニングの恩恵を受けるモデル更新
- 非常に長い録音に対する分散コンピューティング
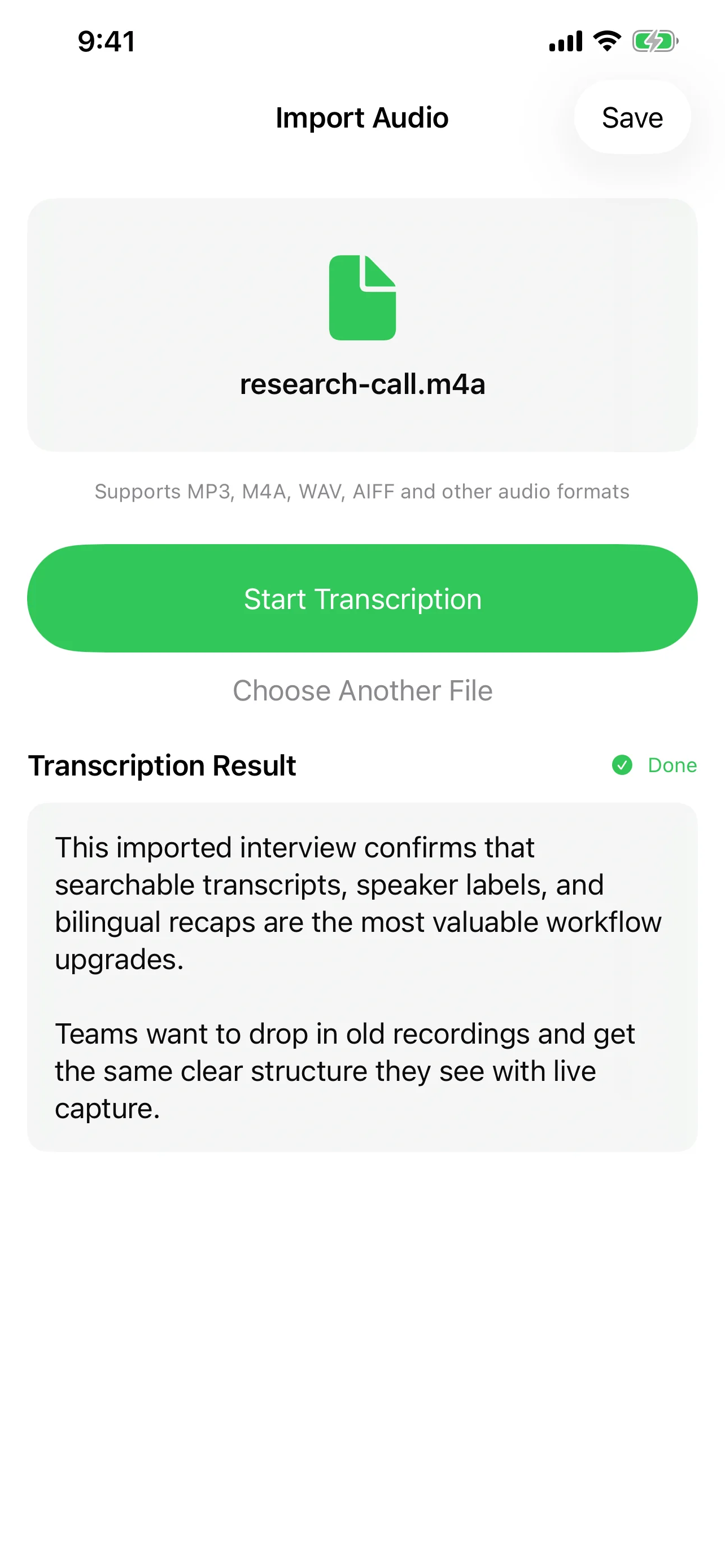
コスト:無料 vs 従量課金
オンデバイス文字起こしは無料です。処理はすでに所有しているハードウェアで行われ、OSに同梱されたモデルを使用します。APIコール、使用量ティア、月額請求はありません。
SpeechyのローカルMLXモデル(Qwen、Gemma、Llama)は、このコスト優位性をAI後処理(要約、アクション抽出、テキスト修正)にも拡張します。
オフライン利用:決定的な差別化要因
クラウド文字起こしにはインターネット接続が必要です。飛行機の中、地下の会議室、電波のない地方では使えません。
Speechyの完全なパイプライン(録音、文字起こし、話者分離、ローカルモデルによるAI要約)はネットワーク接続なしで機能します。フォールバックモードではなく、フル機能です。
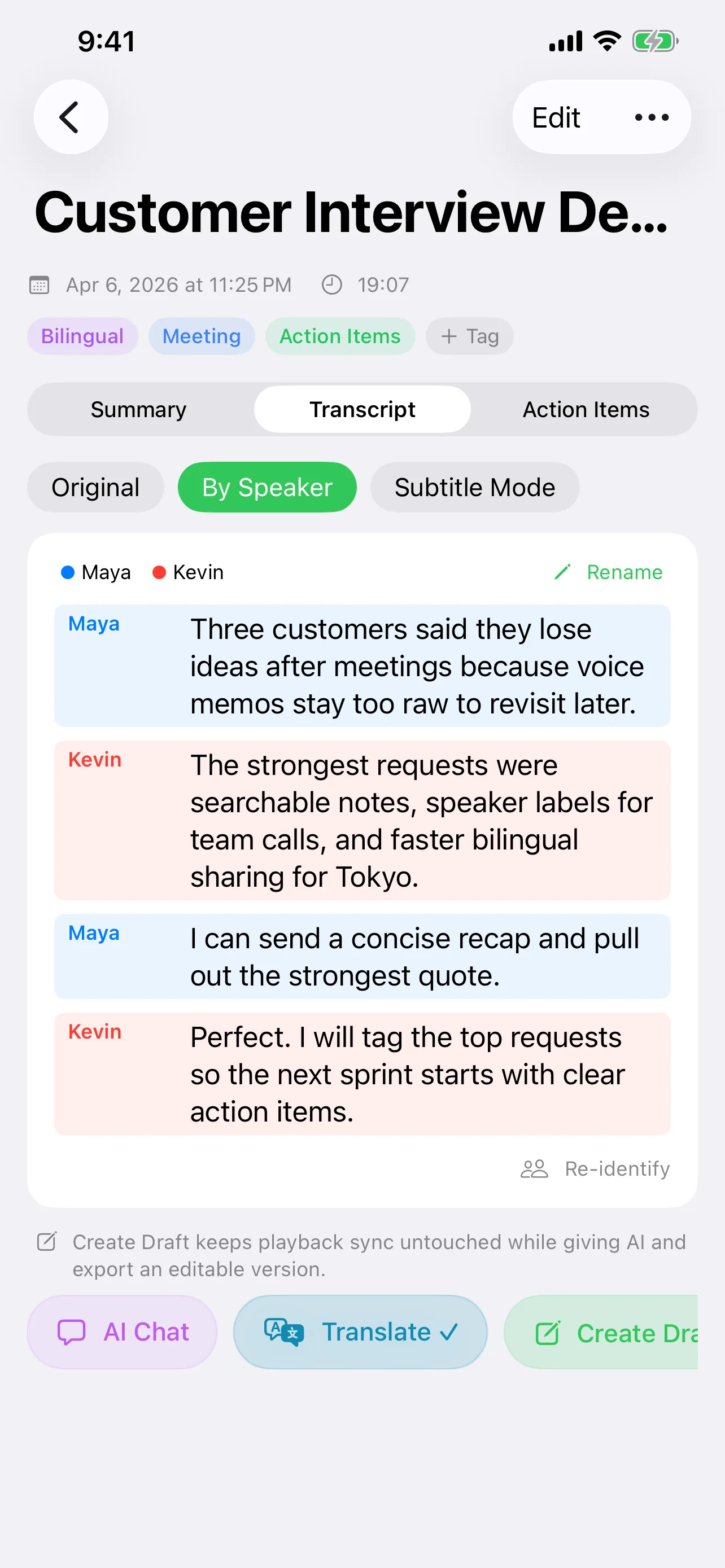
Speechyが両方の世界を橋渡し
これは二者択一である必要はありません。Speechyはローカルファースト戦略で設計されています:
- デフォルトはオンデバイス — iOS 26のSpeechAnalyzerで文字起こし。音声はローカルに留まり、結果は即時、オフラインでも動作。
- ローカルAI処理 — Apple IntelligenceとMLXモデルが要約、修正、分析をクラウド不要で処理。
- 選択時のみクラウド — より大きなモデルが必要な場合、GPT-4.1、Claude、Geminiを利用可能。
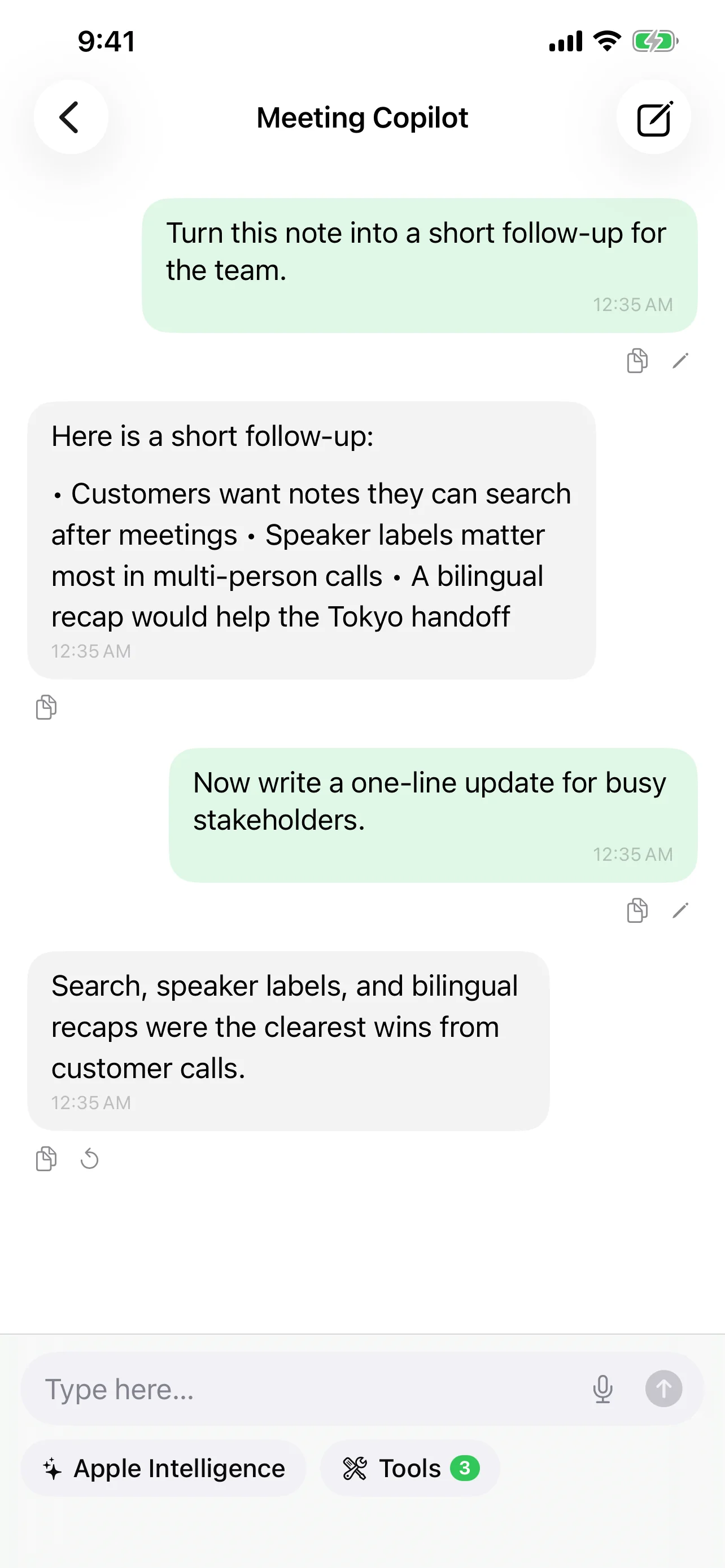
音声認識の未来は、どちらかを選ぶことではありません。各瞬間に適切なツールを使う自由を持ち、データの制御を維持することです。
Speechy を無料で試す
iPhone・iPad・Apple Watch 対応
