设备端 AI 转录 vs 云端转录:隐私、速度与准确度全面对比
深入对比设备端语音识别和云端转录——从隐私、延迟、准确率和成本维度,分析不同场景的最佳选择。
根本问题:你的语音数据去了哪里?
每次你在转录应用中点击「录音」,一个根本性的选择已经被做出:你的音频是留在设备上,还是被发送到千里之外的服务器?这个问题已成为语音识别技术中最核心的分界线。
随着 Apple 在 iOS 26 中推出 SpeechAnalyzer 框架,完全设备端的转录不再是一种妥协——它已经成为云端服务的真正替代方案。但哪种方式更好?答案取决于你最看重什么。
隐私:音频留在本地的意义
设备端转录意味着你的音频永远不会离开手机。语音识别模型在本地运行,将声音转换为文字的过程不需要任何网络请求。对于注重隐私的用户而言,这是革命性的变化。
- 零数据传输——没有音频数据被发送到外部服务器。不存在被截获、泄露或被传唤的可能。
- 无第三方处理——云端服务商通常在共享基础设施上处理你的音频。即使传输过程加密,你的数据也会短暂存在于他人的硬件上。
- 合规保障——对于医疗(HIPAA)、法律(律师-客户特权)、金融(SOX/GDPR)等受监管行业的从业者,设备端处理直接消除了一整类合规风险。
云端转录服务在隐私方面已有显著改善——许多服务提供数据删除政策和加密管道。但没有任何云服务能比得上数据从未离开设备这种简单而彻底的保护。
速度与延迟:即时响应 vs 依赖网络
设备端转录在你开口说话的瞬间就开始生成文字。不需要与远程服务器握手,不需要等待音频上传,不存在往返延迟。Speechy 使用 SpeechTranscriber 实现流式识别,文字随着你的语音实时显示。
云端转录则存在固有延迟:
- 音频需要被采集和打包
- 数据包传输到服务器(50-200毫秒,取决于网络状况)
- 服务器处理音频
- 结果返回到你的设备
在快速 Wi-Fi 连接下,这种延迟可能几乎感觉不到。但在拥挤的蜂窝网络或信号不佳的会议室中,延迟变得非常明显。设备端处理彻底消除了这个不确定因素。
准确度:各有所长
在准确度方面,对比变得微妙。两种方式都不具备绝对优势。
设备端的优势:
- 对常见语言和标准词汇表现优异
- 不受网络条件影响,表现始终稳定
- Apple 的 SpeechAnalyzer 通过 DictationTranscriber 提供自动标点,让原始输出立即可读
- 说话人分离完全在离线状态下完成——Speechy 无需任何云端依赖即可分离和标注多个说话人
云端的优势:
- 更大的模型和更广泛的训练数据能更可靠地处理稀有语言、浓重口音和领域特定术语
- 云端模型持续更新,受益于不断进行的训练
- 对于超长录音,云端服务可以利用分布式计算实现更快的批处理
这个差距正在快速缩小。2026 年的设备端模型已经能够处理两年前还需要云端处理的场景。对于大多数日常转录——会议、语音笔记、访谈——设备端准确度已经完全够用。
成本:免费 vs 按量付费
设备端转录有一个极具吸引力的成本结构:它是免费的。处理发生在你已经拥有的硬件上,使用操作系统内置的模型。没有 API 调用,没有用量分级,没有月度账单。
云端转录服务通常按处理的音频时长计费。偶尔使用可能费用不高。但对于重度用户——记者、研究人员、内容创作者——成本迅速累积。单次一小时的访谈通过云端 API 转录可能需要花费数美元。
Speechy 的 本地 MLX 模型(Qwen、Gemma、Llama)将这一成本优势延伸到了 AI 后处理。摘要生成、行动项提取、文本修正都可以在设备上以零边际成本运行。
离线可用性:决定性场景
云端转录需要网络连接,这是不可回避的前提。如果你在飞机上、地下室会议室或没有信号的偏远地区录制对话,云端转录完全无法工作。
设备端转录在你的手机能工作的任何地方都能工作。Speechy 的完整流程——录音、转录、说话人分离,甚至通过本地模型进行 AI 摘要——都无需任何网络连接即可运行。这不是降级模式,而是完整体验。
对于无法预测下一次重要对话会在哪里发生的专业人士而言,离线能力不是锦上添花——而是刚需。
Speechy 如何融合两种方案
真正的洞察在于:这并不必须是一个非此即彼的选择。Speechy 围绕本地优先策略设计,让你同时获得两种方案的最佳体验:
- 默认设备端处理——转录使用 iOS 26 的 SpeechAnalyzer 框架。音频留在本地,结果即时呈现,离线同样可用。
- 本地 AI 处理——Apple Intelligence 和 MLX 模型(Qwen、Gemma、Llama)处理摘要、修正和分析,无需云端依赖。
- 按需使用云端——对于需要更大模型的任务,Speechy 提供 GPT-4.1、Claude 和 Gemini 集成。何时使用由你决定。
- 自定义端点——高级用户可以连接任何 OpenAI 兼容的 API 端点,包括自托管模型,完全掌控数据流向。
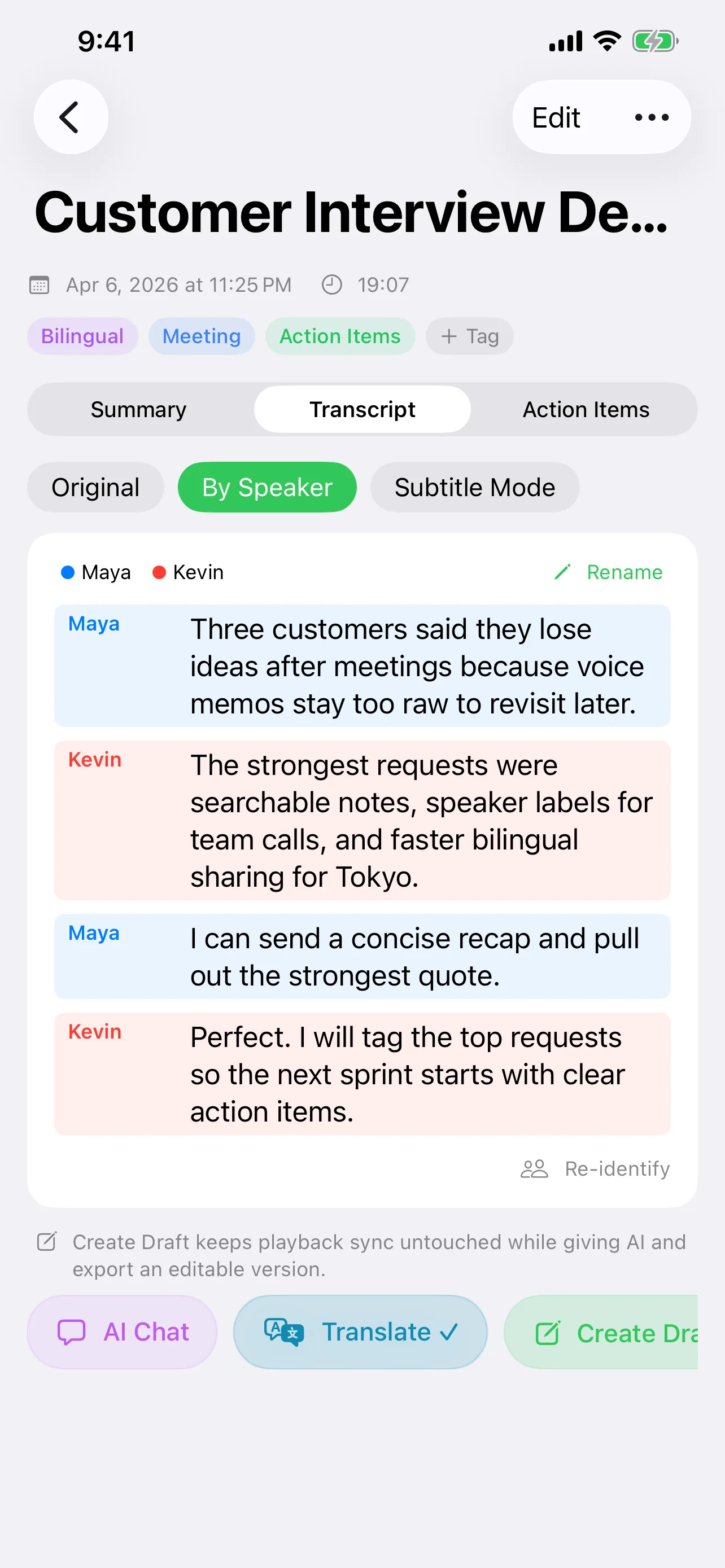
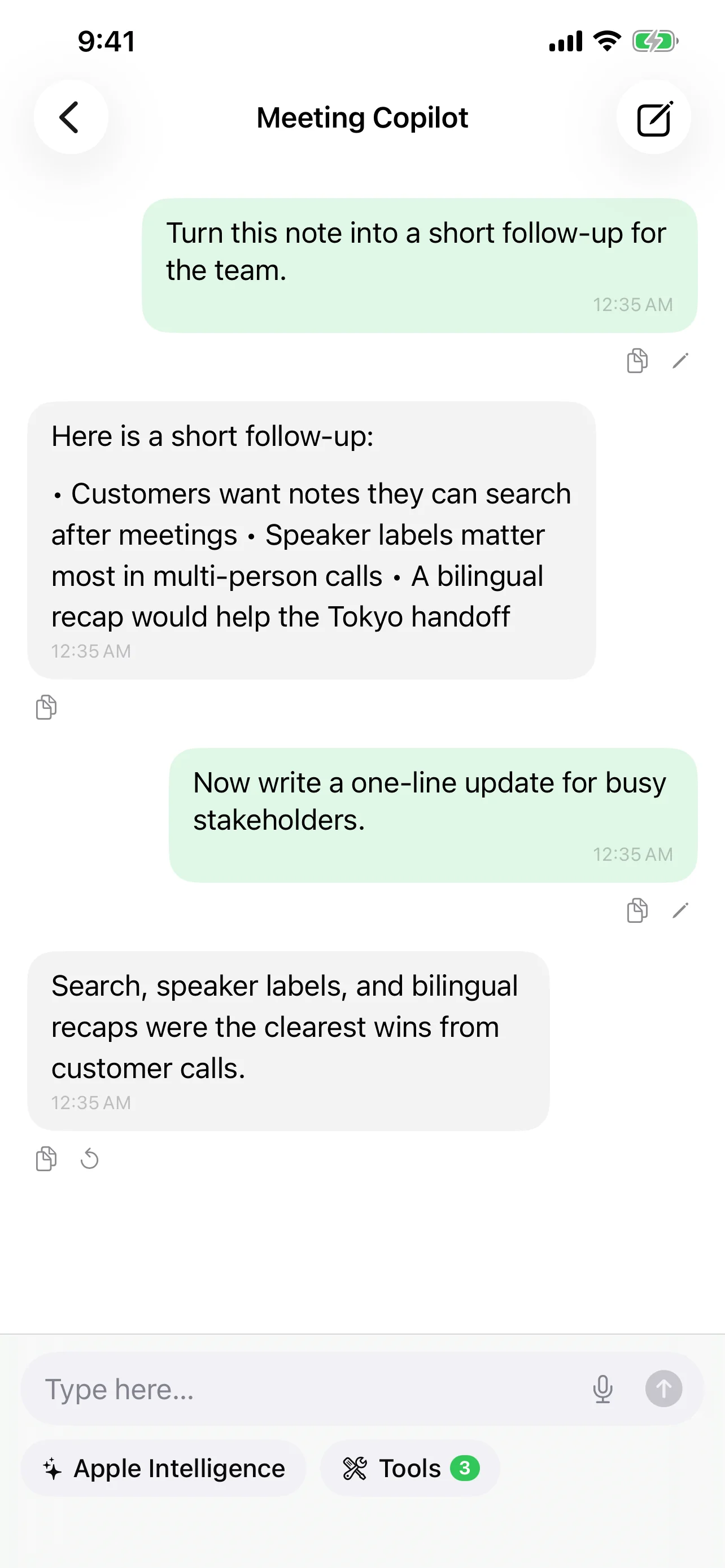
这种架构意味着你永远不会被锁定在某一种方式上。快速语音笔记完全留在设备上。复杂的多小时录音可以发送到云端模型进行更深入的分析——但前提是你明确选择这样做。
如何做出正确选择
以下是一个实用的决策框架:
- 选择设备端——当隐私至关重要时,当你处于离线或网络不稳定环境中,用于日常转录任务,或者当成本是考量因素时。
- 选择云端——当你需要在专业内容上获得最高准确率,处理超长录音,或者需要只有最大模型才能提供的能力时。
- 选择混合模式(Speechy 的默认方式)——当你希望享受本地优先的便利,同时保留按需升级到云端能力的选项时。
语音识别的未来不在于选择某一方。而在于拥有自由,为每个场景使用最合适的工具——并在这个过程中始终掌控自己的数据。
免费试用 Speechy
支持 iPhone、iPad 和 Apple Watch
